/ 4 min read
Recursive Filters: SMA, EMA, Low‑Pass, and a Tiny Kalman
While exploring optimizers I fell down the rabbit hole of recursive filters. This post is a compact, practical tour of smoothers you can use when measurements are noisy but latency and compute are tight. We’ll keep the math minimal, the intuition high, and focus on when and why to use SMA, EMA/low‑pass, and a tiny 1D Kalman.
If you are here just for code, my Kaggle Notebook can be found here.
Why recursive filters
Recursive filters shine when compute and memory are scarce, or when data arrives as a stream and you must react immediately.
- O(1) memory: you keep just the last state (and maybe a running sum) rather than a long buffer.
- O(1) compute per sample: one or two multiply‑adds per step—perfect for microcontrollers and tight loops.
- Online, low‑latency: produce an updated estimate as soon as a sample arrives; no need to wait for a full window.
- Simple, robust implementations: easy to port, vectorize, or run in reduced precision.
- Graceful with irregular sampling: updates are incremental and don’t assume batch availability.
Intuition note
Recursive filters that we’ll use, all use constant‑size state. That’s why they’re common in embedded systems, robotics control loops, mobile sensor smoothing and telemetry.
Notation
- : the raw observation at time step .
- : the smoothed estimate at time .
- : window size (for moving averages).
- : smoothing factor (higher = smoother, but laggier).
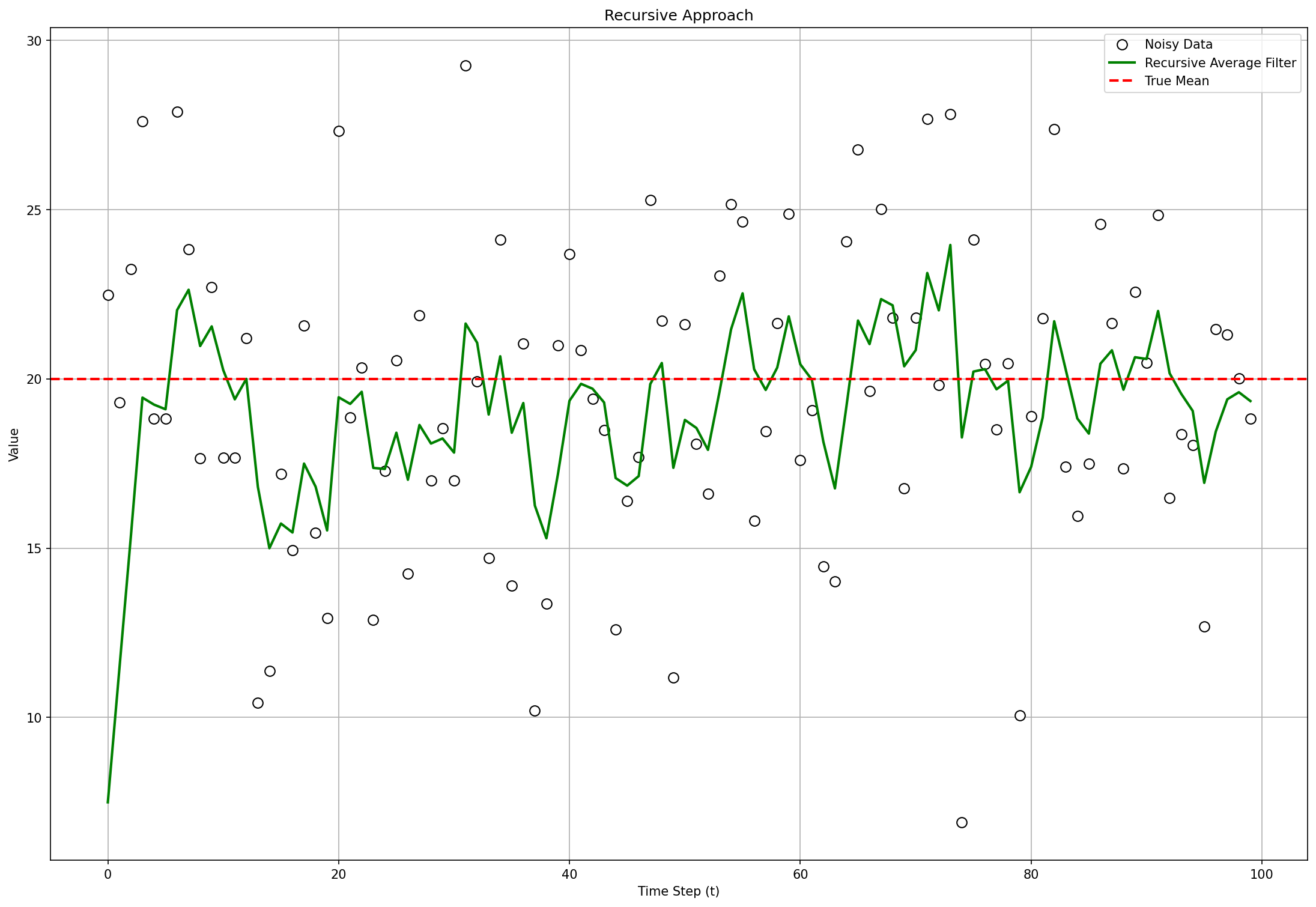
Recursive Average Filter (also known as EMA)
The one‑liner you’ll use most:
Many libraries choose directly; our example consists of data points and we define alpha as to make notation easier to hold in our memory.
Intuition note
This behaves like a leaky integrator. Bigger forgets the past more slowly (smoother, more lag). The initial line takes a few iterations before it can get closer to the real mean value.
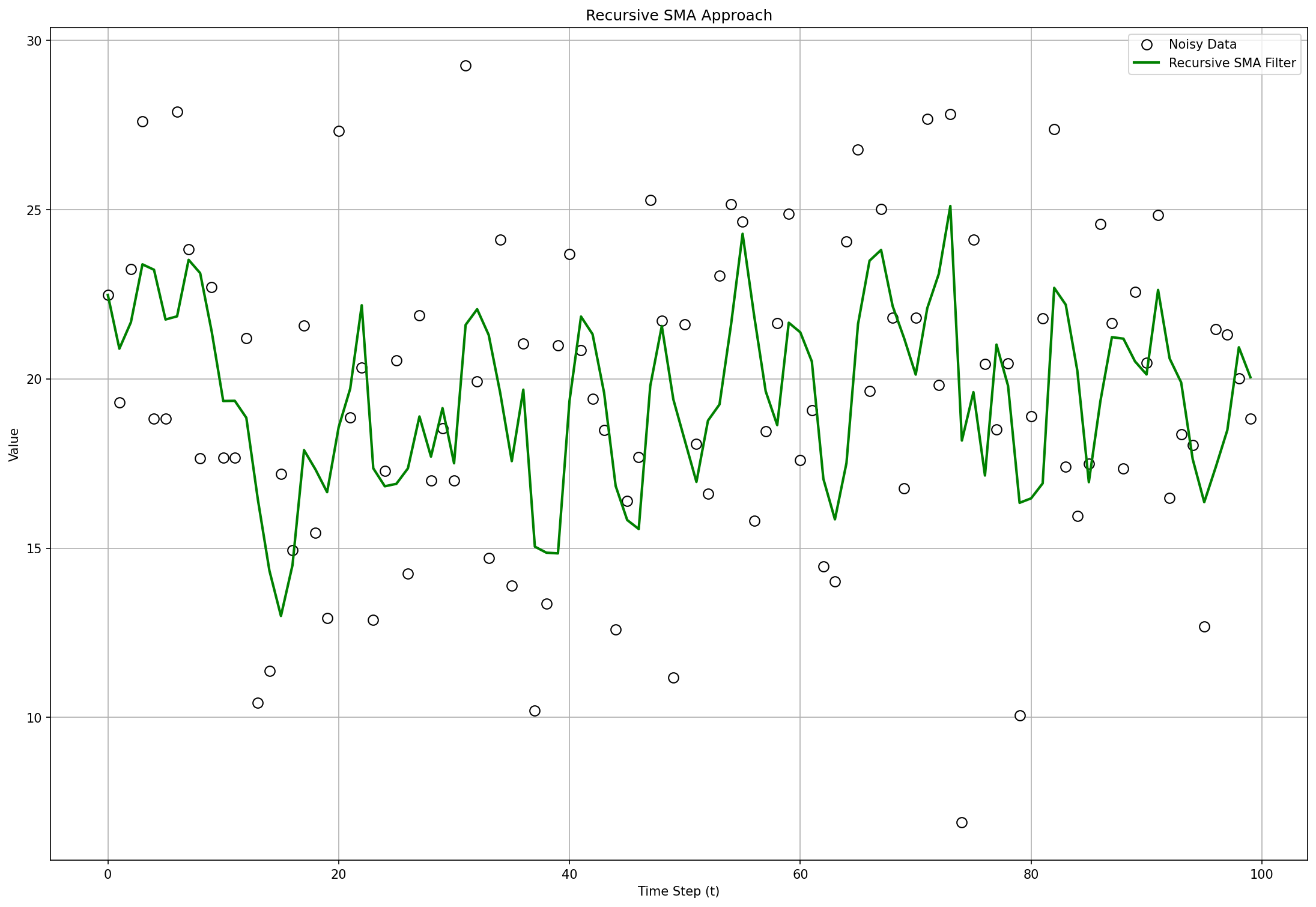
Simple Moving Average (SMA)
Windowed average over the last samples:
Intuition note
Great at crushing noise, but it lags and needs a buffer of the last points. Spikes are “diluted” equally across the window.
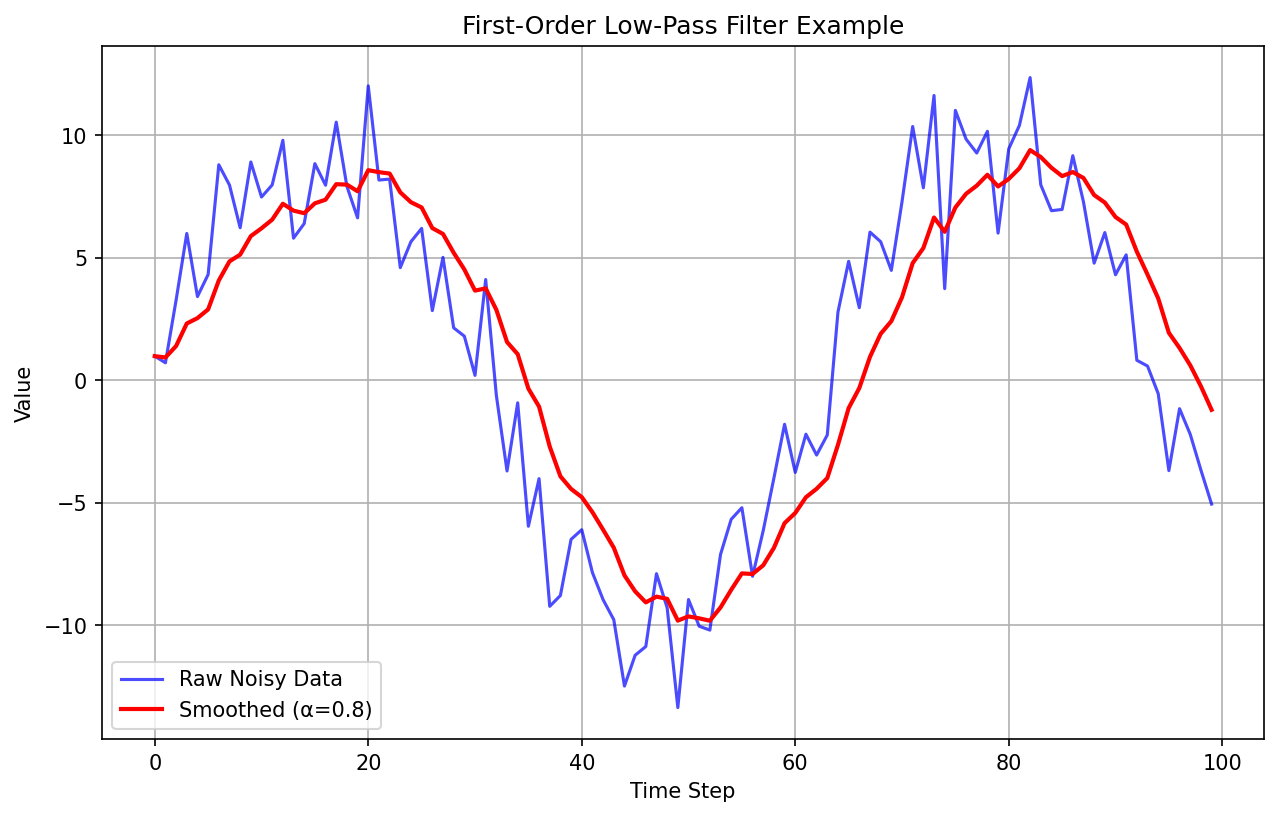
First‑Order Low‑Pass Filter
In discrete time, the classic low‑pass is algebraically the same as the EMA:
Different name, same form. You pick to trade off noise suppression versus responsiveness.
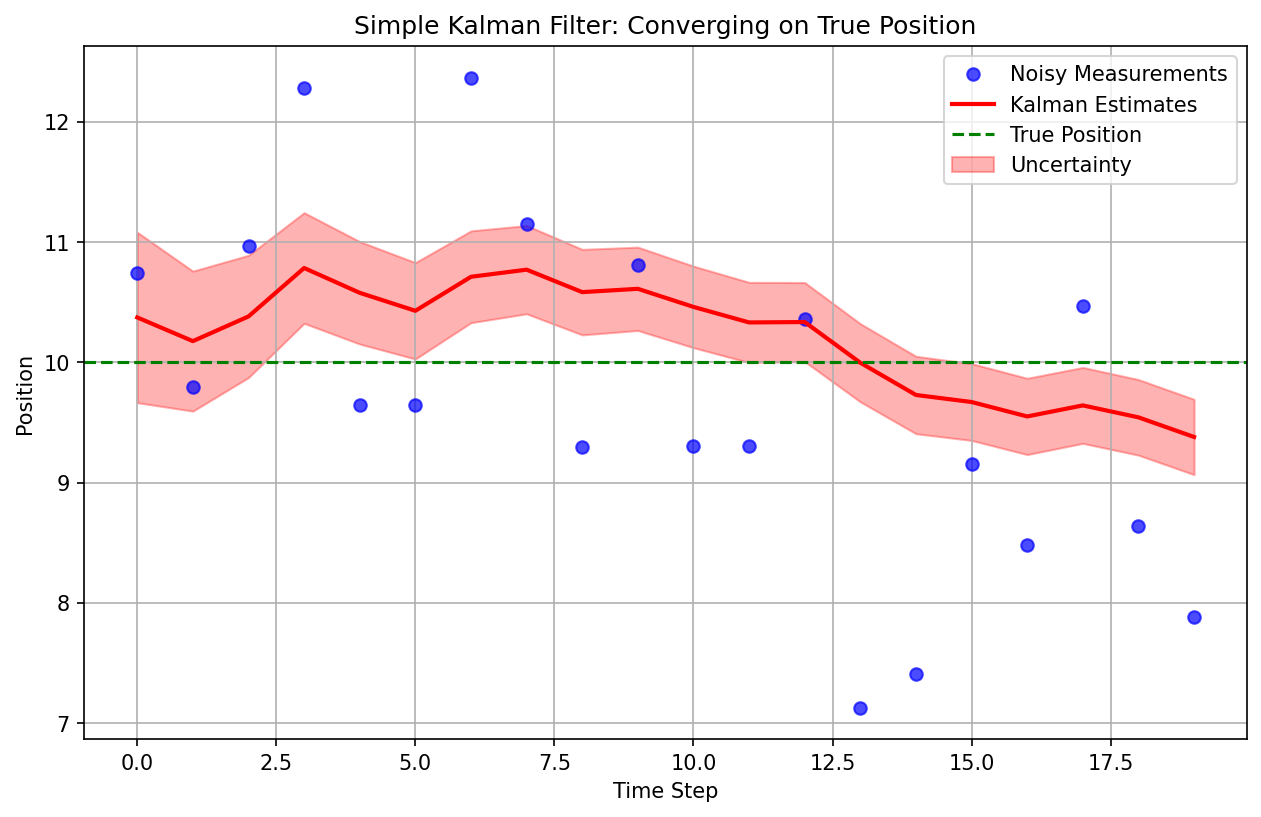
A Tiny 1D Kalman Update
This is just scratching the surface of a Kalman Filter - a tiny 1D Kalman Update. This is my first attempt at building intuition before I can jump to an actual KF.
When you know your sensor noise () and process noise (), Kalman gives you an adaptive gain that automatically balances trust between the prediction and the measurement. For a constant‑value model ():
Predict:
Update:
Intuition note
If measurements are noisy (large ), shrinks and you trust the prior more. If the process is volatile (large ), grows and increases—trust the new measurement more.
Choosing parameters
- SMA window : larger = smoother but laggier. Needs a buffer.
- EMA/low‑pass : start around –. Tune by eyeballing lag vs. noise.
- Kalman : set to your sensor variance; set to how much you expect the latent to drift between steps.
What next?
SMA is simple and robust; EMA/low‑pass is the default for streaming; and a tiny Kalman filter adds principled adaptivity when you can estimate noise. Two first filters are easy to implement, Kalman though was simplied to its 1D version. An actual Kalman Filter is way more complicated and it should be the subject of my future learning. Hopefully there will be a text about it of a decent quality.
Standing on the shoulders of giants
Resource that I used:
- Dr. Shane Ross videos on the topic
- Kalman Filter explained simply